Public Safety News Analysis (Engineering)
Project link: https://github.com/eric-mc2/quantify-justice-news-geos/
This post describes the technical implementation of the public safety news analysis.
Research Question
What is the spatial distribution of crime news coverage across Chicago?
I decompose this question into smaller machine learn-able tasks:
- Is the article crime-related? (classification)
- Which sentences in the article describe the crime incident? (classification)
- Which words refer to a location? (named entity recognition)
- Which location words relate to the crime incident? (dependency parsing)
- Which neighborhood is this in? (classification)
Data Sources
News articles: The data is a sample of 713k articles from the Chicago Justice Project’s news archive from 201X onwards.
News articles serve as training data for all five model stages.
Chicago geographies: Downloaded community area boundaries, neighborhood boundaries, street network from City of Chicago data portal.
Geometries are used for exact matching and classification when possible. They are also used to generate synthetic training data for neighborhood classification.
Models
Article Classifier: I classify articles as crime-related or not, based off of the article title, using Spacy’s off-the-shelf binary text classifier (for the proof of concept, a unigram BOW).
Articles tagged as non-crime-related are passed through the rest of the pipeline with no further processing.
Sentence Classifier: I classify whether each sentence from the article body describes the WHO, WHAT, HERE, or WHEN of the crime incident, using Spacy’s off-the-shelf multi-label text classifier (for the proof of concept, a unigram BOW).
Location Recognition: I created a custom Spacy Pipeline component for NER:
- Use Spacy’s PhraseMatcher to efficiently check for exact matches against a list of all Chicago street names, intersections, address blocks, neighborhoods, community areas, and “sides” (e.g. North Side).
- Run Spacy’s pre-trained (tok2vec) NER model to identify more GPE (counties, cities) and FAC (highways, airports) entities.
- Clean up and merge entities.
- Tag entity with fine-grained location type, based on previous matching method.
This combination of rules-based and machine-learning consistently fixes common cases missed by the model, e.g. consolidating “(1300)[number] block of (North Webster Ave)[street]” into “(1300 block of North Webster Ave)[street]”.
Dependency Parsing Not implemented yet. For the proof of concept, I include sentences that were positive matches for both sentence classification and location entity recognition.
Sentences that were negative matches for either stage are passed through the rest of the pipeline with no further processing.
Community Area Classification
- Predict neighborhood using Spacy’s off-the-shelf multi-class text classification model (for proof of concept, bi-gram BOW). The training data for this model is half hand-labeled, half synthetic data sampled from the city geometries.
- Tag blocks, intersections, and neighborhoods with their known community area, based on their spatial relationships.
- Merge labels from machine learning and exact methods.
Infrastructure
I’m using Dagster to explicitly declare and manage the separate pre-processing, training, evaluation, and tuning steps per pipeline stage.

Pipeline
I have a bias towards file-centric pipeline declarations like Makefiles and dvc, particularly the way these tools abstract where data is located away from the code operating on the data.
Data Discovery
My goal is to make it easy to quickly scan the order that data files are created and the relationships between inputs, processing scripts, and outputs. First, I define all data paths in an external config file, which is organized by stage:
# pipeline.yaml
raw:
article_text: "raw/articles.parquet"
art_relevance:
article_text_labeled: "art_relevance/articles_labeled.jsonl"
article_text_train: "art_relevance/articles_train.spacy"
article_text_test: "art_relevance/articles_test.spacy"
sent_relevance:
article_text_labeled: "sent_relevance/articles_labeled.jsonl"
article_text_train: "sent_relevance/articles_train.spacy"
article_text_test: "sent_relevance/articles_test.spacy"
These paths are relative, allowing the data folder itself to be environment-specific, which is checked when the config is loaded. (For local development it is just “./data” within the project folder. For running on Colab, it is a Google Drive path “/gdrive/MyDrive/…/data”).
# script.py
from scripts.utils import Config
config = Config()
print(config.get_data_path("raw.article_text"))
"/absolute/path/to/project/data/raw/newsarticles.parquet"
Stage Declarations
My goal is to make this file really compact
and to highlight a) the logical stage dependencies and b) the input output
flows. To achieve this, I separate the actual processing logic to a different
file operations.py. And as before, the actual data locations are
isolated and loaded through the config file.
# scripts/preprocessing/assets.py
import dagster as dg
from scripts.utils import Config
from scripts.preprocessing import operations as ops
config = Config()
@dg.asset
def extract(description="Unzip raw data"):
in_path = config.get_data_path("raw.zip")
out_path = config.get_data_path("raw.article_text")
ops.extract(in_path, out_path)
# scripts/art_relevance/assets.py
import dagster as dg
from scripts.utils import Config
from scripts.art_relevance import operations as ops
config = Config()
@dg.asset(deps=[extract], description="Split labeled data for training.")
def split_train_test():
in_path = config.get_data_path("art_relevance.article_text_labeled")
out_path_train = config.get_data_path("art_relevance.article_text_train")
out_path_test = config.get_data_path("art_relevance.article_text_test")
ops.split_train_test(in_path, out_path_train, out_path_test)
This may look like boilerplate, but I like it’s cleanliness. The logical separation
makes it very clear that assets.py is about defining arbitrarily complicated Dagster
dependencies, whereas operations.py is about defining arbitrarily complicated data manipulation.
Training
Annotation
My goal is to prototype each sub-model quickly, get a sense of the overall performance, get a sense of which model need improvement. I sample an hour’s worth of articles per model, and annotate them in Label Studio.
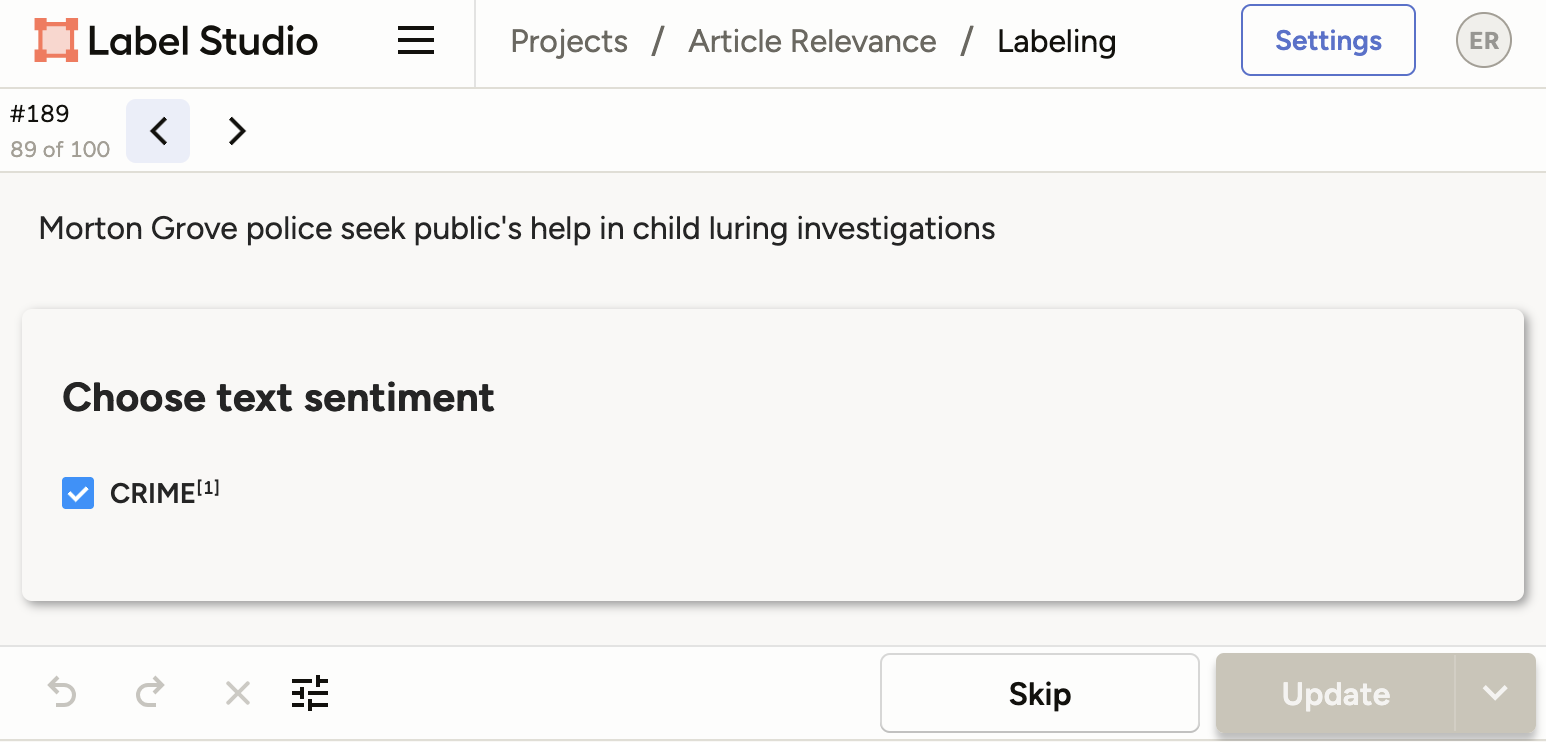 A positive example.
A positive example.
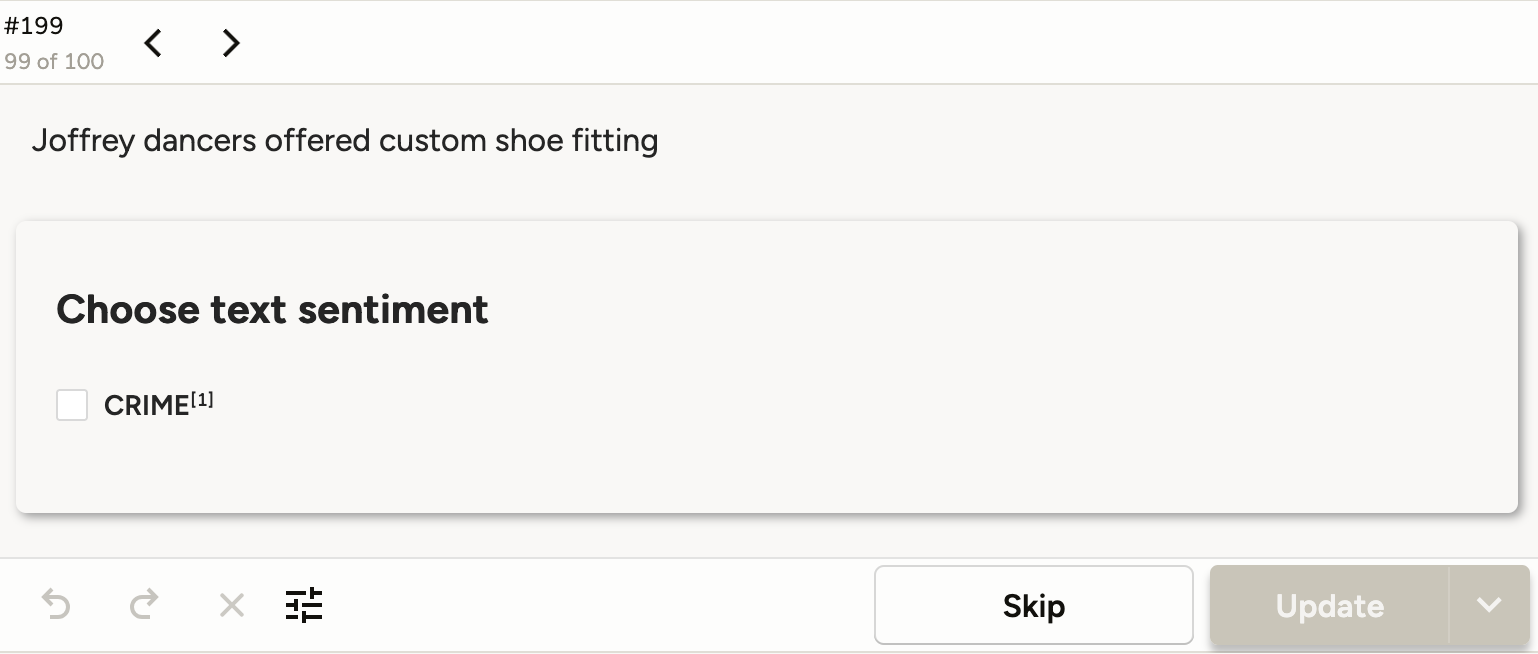 A negative example.
A negative example.
Tuning
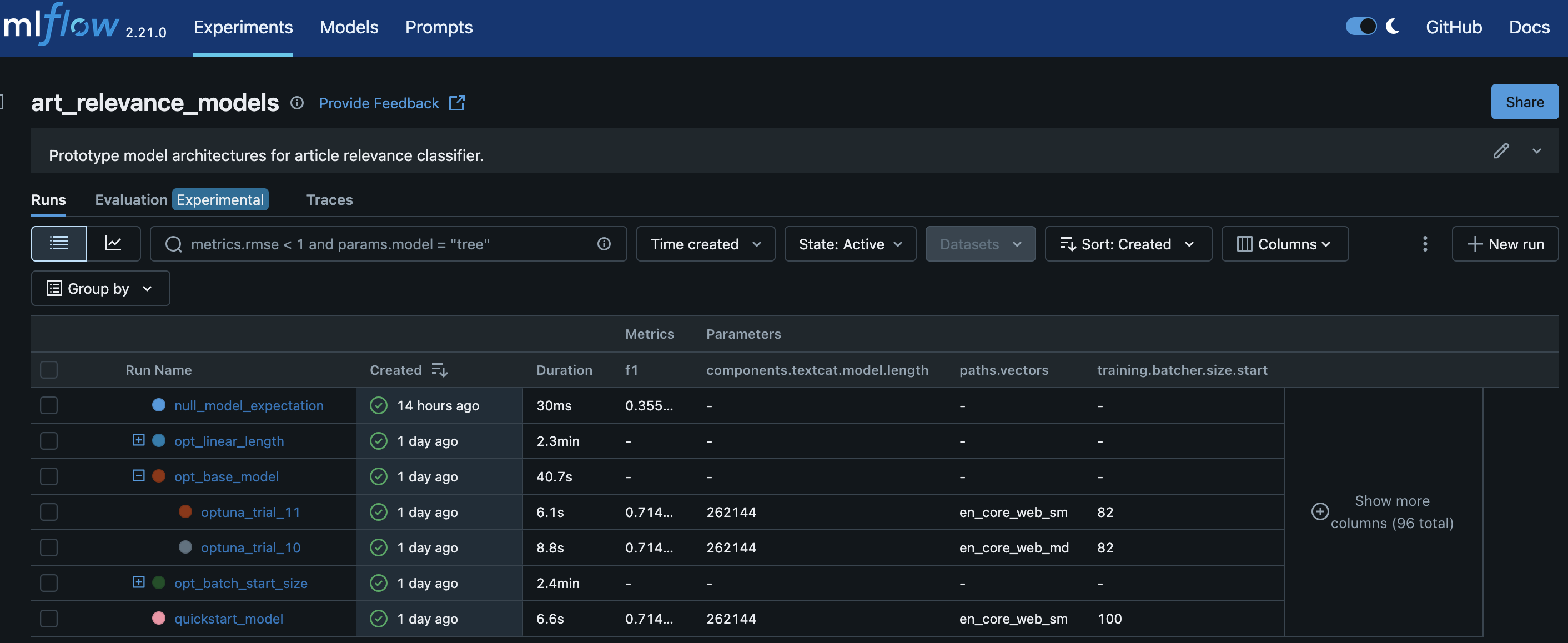
I am using MLFlow to track model experiments and
Optuna for hyperparameter tuning. I load
the spacy config file, flatten it like {"nested.key.param1": val1, "nested.key.param2": val2}
and dump the full parameter list into MLFlow. This way I’m never missing a baseline
parameter value if I run a new experiment, even though 99.9% of the values are unchanged run-to-run.
So far, hyper-parameters are not significantly altering performance. This is likely due to my small sample size (200-400 examples). The validation set is so tiny (holding out 10%), there isn’t enough variation in it for the models to predict differently.
I compare the classification models to a “null model”: randomly predict the positive class according to the frequency of positive values in the training set.
Downstream Models
In production, the sentence classifier will only see sentences from articles which the article classifier has labeled as “crime-related”. In other words, its data distribution is conditional on the article classifier. To mirror this aspect during training, I take an independent sample from the raw data and pass it through the article classifier to filter relevant articles. I pre-process the article text, including breaking it into sentences. And annotate the sentences by hand in Label Studio.
